Created by Carrie Utter
With the widespread information that can be found on the internet, manually searching for data can be tedious and time-consuming. Automation through web scraping is a strategy that many companies and individuals adopt in order to parse information from various sources quickly. Web scraping can be a powerful tool but there are some challenges when trying to parse data that could continuously change.
Background
In addition to being a software engineer at Snapsheet, I am a soccer referee on the weekends and I spend a lot of my time looking through the various referee scheduling websites for open games. Different soccer leagues and tournaments use different websites, and it can be annoying to flip back and forth between them to figure out the optimal schedule. In addition, I found myself spending hours on end sifting through the various locations, trying to figure out which games were the closest to my home. Once I’ve signed up for these games, the websites don’t have calendar integrations to make exporting the schedule into a central location. This is where I got the idea to automate the process. I learned how to scrape websites in order to more efficiently find game information and put it all in one place.
Building the Parser
Most of my programming experience is in Ruby on Rails, Java, and SQL. For this project, I wanted to teach myself a new language. Python is a widely used language and I figured it would be fairly easy to pick up. A friend had suggested Python’s Beautiful Soup package was a good tool for HTML parsing. Thus, I learned how to combine Beautiful Soup with Python’s requests package to web scrape websites.
The first step in web scraping is knowing what information you are trying to scrape. For me, I need to log into the website and see the list of games I have signed up for and put them in my Google Calendar so I can have a single source of truth to look at for my soccer games. But how do I get Python to login for me?
Inspecting The HTML
The first step is to figure out the login and make sure the session is stored for other pages. Chrome dev tools was a good place to start. Using this we can inspect the request the website makes in order to log into the system as shown in Image 1. We can see what POST request is being made and then emulate that within our code.
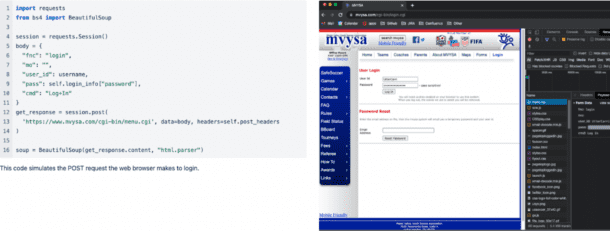
If all goes well, we would see in that BeautifulSoup object the same HTML content as the page as if we had logged in using a browser. From here, I was able to continue this process until I got to the page with the game data I was looking for. This is where inspecting the elements on the page becomes really important. Below is the page with the relevant data that needs to be parsed:
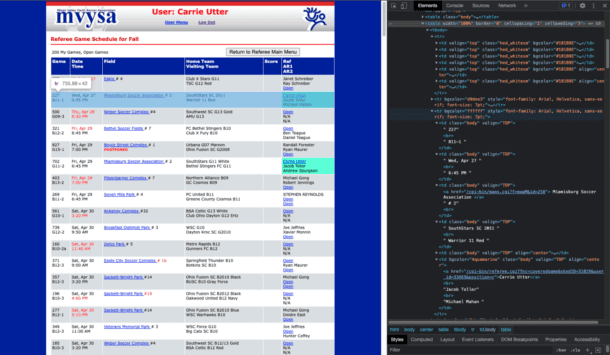
From this HTML, we can see a deeply nested table. In order extract the data needed, we must code to the structure of the page. This makes our code very brittle to any changes the website might make but it’s the only way to get the data needed. It requires the scraper to know exactly how the page will be formatted. Using BeautifulSoup, we can parse this HTML for the games we need. Luckily, most referee websites use tables to show the list of games. Although they might be slightly different, the parsing concept is the same. First we can get the table we are looking for with:

Then we can get all the games with games = main_table.find_all(‘tr’). This corresponds to each row we are looking for which is a separate game. Finally, we can manipulate the game data for each row. This requires a lot of knowledge about the page. Here’s an example of how I extract data:

For my initial use case, I take note of if my name shows up in the list of referees and if so, I connect the game to my Google Calendar to sync it with games on my schedule from other websites.
Modularity
Once I got the main scraper working for one website, I broke the code into more modular classes so that the scraper is scalable for different websites. My project structure allows for only needing to create a new scraper to parse the HTML data. Once game data is abstracted, adding the game to Google Calendar is the same regardless of the website.
Challenges of Web Scraping
Throughout my experience with this scraper, there were a few challenges to overcome in the process. Some challenges are easier to combat than others and depend on the type of website the scraper is making requests against.
Authentication
All the websites I needed to scrape required login credentials. Using Python’s requests package made it easy to login and reuse the session cookies for the next requests.
Changing HTML
A large challenge arises when the website you are scraping decides to change its HTML that the scraper is dependent upon. I came across this issue when one of my websites decided to put the table of games inside another table for some unknown reason. Ways to mitigate this issue would probably be to look for CSS classnames or text that most likely won’t change, but you can never be certain since the site could change at any point.
Dynamically Loaded Pages
Some websites dynamically load content on the page depending on what the user is doing on the page. Web scraping these sites involves using an asynchronous parser that can wait for the page to render after a simulated action rather than the HTTP request.
Rate Limiting
Some websites have rate limiting that might block requests if the server detects there are a large number of requests coming from the same IP address. I ran into this issue a few times where my scraper was running too fast for the page to handle the simultaneous requests. Adding sleeps into the web scraper can make it more aligned with human behavior.
Periodic Scraping
With web scraping, there’s no way to get live updates to the data other than running it manually, or having the script run on a timer.
Conclusion
Web scraping has its challenges and should be used when there are no alternative ways to receive the data you are looking for. I would much prefer working with an API over scraping for the data; however, I’m always interesting hearing other opinions on the topic. Unfortunately, I will be moving from my current area so my current scraper will be obsolete but I have a good foundation now for future development. I eventually discovered the requests-html package that uses Beautiful Soup and Requests together already. I started working with this package but have not had the chance to create a Pull Request with it yet but it’s what I would recommend for web scraping going forward. My full web scraper can be found here: GitHub – uttercm/referee-scraper: For my own scraper of Ohio’s referee assignments .

Subscribe for Updates
Top 5 Reasons Why You Should Subscribe
-
#1
Stay up-to-date on industry news and trends
-
#2
Learn about claims management best practices
-
#3
Gain insights into customer behavior and preferences
-
#4
Discover new technologies and innovations
-
#5
Engage with a community of industry professionals
Appraisals
Reduce cycle time and improve appraisal accuracy
Claims
Claims management with our modular, end-to-end solutions
Payments
Deliver payments effortlessly with automated tools and no-code workflows